
今日内容: 单链表
思考题目:
声明描述学生信息的结构体, 定义三个结构体变量来描述三个学生信息
要求:
可以通过第一个学生找到第二个学生,
可以通过第二个学生找到第三个学生.
student.c
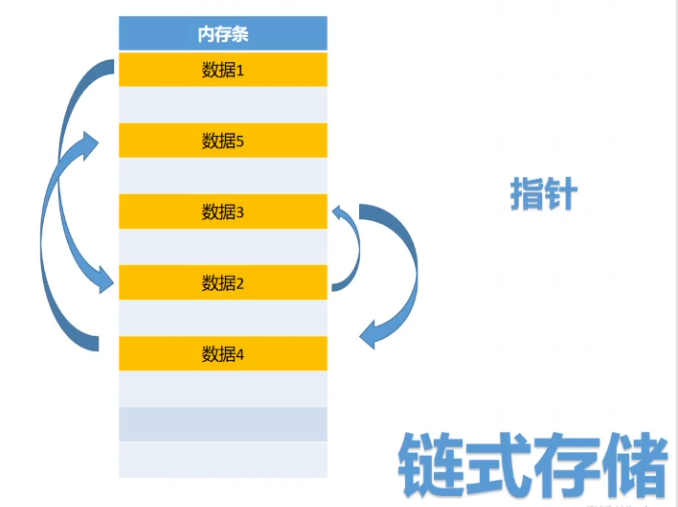
- s1, s2, s3 – 三个结构体类型变量 – 内存之间并不连续
- s1, s2, s3 – 三个结构体类型变量 – 元素之间具有先后关系
链式存储结构
常用的处理措施 –
给链式物理结构的元素 – 添加两个新的元素
头结点 – 表示链式物理结构的起始 – 头结点的下一个结点 – 第一个有效结点
尾结点 – 表示链式物理结构的结束 – 最后一个有效结点的下一个结点 – 尾节点
头结点和尾节点 不存储任何的有效数据
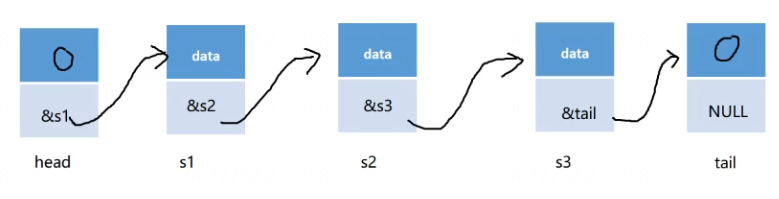
不需要头结点和尾结点 - 可以不需要
#include <stdio.h>
//声明描述学生信息的结构体
typedef struct student{
char name[32];
int age;
struct student* next;//保存下一个学生信息的首地址
}stu_t;
int main(void){
//定义初始化三个学生的信息
stu_t s1 = {.name = "贾宝玉", .age = 18, .next = NULL};
stu_t s2 = {.name = "林黛玉", .age = 17, .next = NULL};
stu_t s3 = {.name = "薛宝钗", .age = 19, .next = NULL};
stu_t head;
stu_t tail;
//s1存储s2的地址, s2存储s3的地址
head.next = &s1;
s1.next = &s2;
s2.next = &s3;
s3.next = &tail;
tail.next = NULL;
//访问结构体中的成员
//printf("%s, %s, %s\n", s1.name, s2.name, s3.name);
//通过第一个学生, 打印第二个学生的信息, 通过第二个学生打印第三个学生的信息
//1.next太长了
//2.如果s1没有了, s1修改为s2, 维护起来非常麻烦
//s1.next = &s2
//s1.next->next = &s3
printf("%s %s %s\n", s1.name, s1.next->name, s1.next->next->name);
//利用head和tail来优化遍历打印每个学生姓名
for(stu_t* pnode = &head; pnode != &tail; pnode = pnode->next){
stu_t* pmid = pnode->next;
if(pmid != &tail)
printf("%s:%d\n", pmid->name, pmid->age);
}
return 0;
}pnode变化范围
起始 – head(头结点)
结束 – 最后一个有效结点
pmid永远是pnode的下一个结点
变化范围
起始 – 第一个有效结点
结束 – tail(尾结点)
上述代码是一个单链表吗 – 不算 – 链式存储结构
内存 + 解决方法 – 数据结构
顺序结构 – 链式结构
顺序 – 缺点 – 插入和删除的时候需要移动大量元素, 耗费大量时间
– 有点 – 随机访问能力 – 数组下标
链式结构 – 插入 删除 简单
– 内存之间并不连续
– 从前一个数据得到后一个数据 – 耗费大量时间
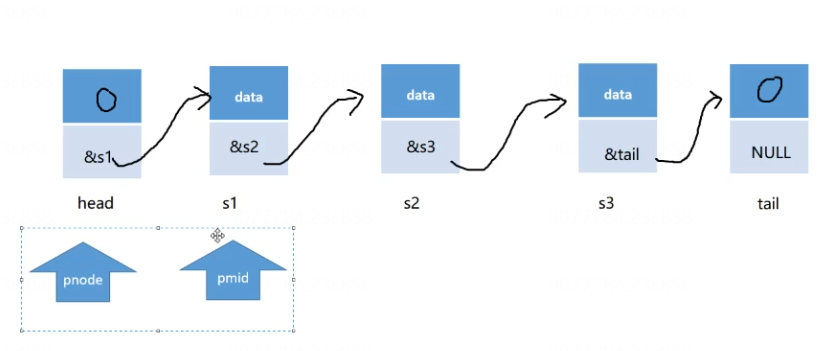
单链表 – 每个节点内存不一定连续, 通过一个元素可以找到下一个元素, 朝一个方向操作
描述结点的结构体类型:
struct node{
结点数据信息;//年龄, 姓名, 结构体, ….
struct node* next;//保存下一个结点首地址
};//将来根据自己的需求将node名字修改为自己想要的名字, 例如:student, employee, …
描述整个单链表的结构体类型:
struct list{
struct node* head;//保存头结点的首地址
struct node* tail;//保存尾结点的首地址
};
刚刚构造了一个单链表 – 只有一个头结点和一个尾结点 – 没有任何的有效结点
分析:
1.真实存在的头结点和尾结点
struct node* head;
struct node* tail;
两个指针 – 头结点和尾结点的元素 – 不存在
2.插入新的结点
pfirst – 要插入的前一个结点
pmid – 指向要插入的后一个结点
升级:
1.头插函数
新的结点插入到头结点和第一个有效结点之间
void list_add_head(list_t* list, int data){}
2.尾插函数
新的结点插入到最后一个有效结点和尾结点之间
void list_add_tail(list_t* list, int data){}
list_add
删除某个结点的函数
mkdir list
vim list.h
#ifndef _LIST_H
#define _LIST_H
//包含公共的头文件
#include <stdio.h>
#include <stdlib.h>
//声明描述结点信息的结构体类型
typedef struct node{
int data;//结点数据
struct node* next;//保存下一个结点的首地址
}node_t;
//声明描述单链表的结构体类型
typedef struct list{
struct node* head;//保存头结点的首地址
struct node* tail;//保存尾结点的首地址
}list_t;
//声明单链表的操作函数
extern void list_init(list_t* list);//初始化
extern void list_travel(list_t* list);//遍历
extern void list_deinit(list_t* list);//释放
extern void list_add(list_t* list, int data);//插入
extern void list_del(list_t* list, int data);//删除
#endif
vim list.c
#include "list.h"
//定义分配新结点并且初始化新结点的函数
static node_t* create_node(int data){
//分配结点内存
node_t* pnew = (node_t *)malloc(sizeof(node_t));
//初始化结点内存
pnew->data = data;
pnew->next = NULL;
//返回新结点内存的首地址
return pnew;
}
void list_init(list_t* list){
//给头结点分配内存
list->head = create_node(0);
//给尾结点分配内存
list->tail = create_node(0);
//首尾相连
list->head->next = list->tail;
list->tail->next = NULL;
}
//定义单链表的遍历函数
void list_travel(list_t* list){
for(node_t* pnode = list->head; pnode != list->tail; pnode = pnode->next){
//1.定义三个游标
node_t* pfirst = pnode;
node_t* pmid = pfirst->next;
node_t* plast = pmid->next;
//2.判断pmid
if(pmid != list->tail)
printf("%d ", pmid->data);
}
printf("\n");
}
//定义顺序插入函数
void list_add(list_t* list, int data){
//1.创建新的结点
node_t* pnew = create_node(data);
//2.遍历查找要插入的位置
for(node_t* pnode = list->head; pnode != list->tail; pnode = pnode->next){
//1.定义三个游标
node_t* pfirst = pnode;
node_t* pmid = pfirst->next;
node_t* plast = pmid->next;
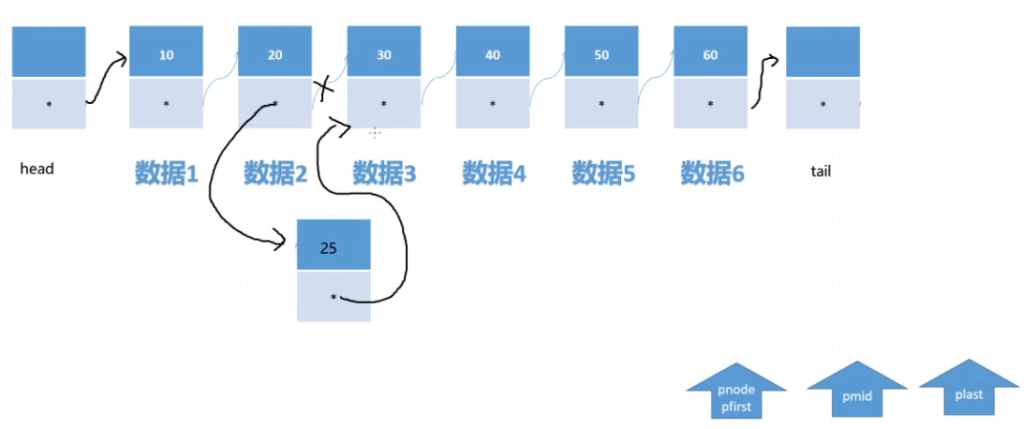
//2.找到要插入到的位置, 插入到pfirst和pmid之间
//head---->10----->20----------->30---->tail
// pfirst pmid
// pnew(25)
//head---->10----->20----------->30----------->tail
// pfirst pmid
// pnew(40)
if(pmid->data >= pnew->data || pmid == list->tail/* 新结点数据在整个链表最大*/){
pfirst->next = pnew;
pnew->next = pmid;
break;
}
}
}
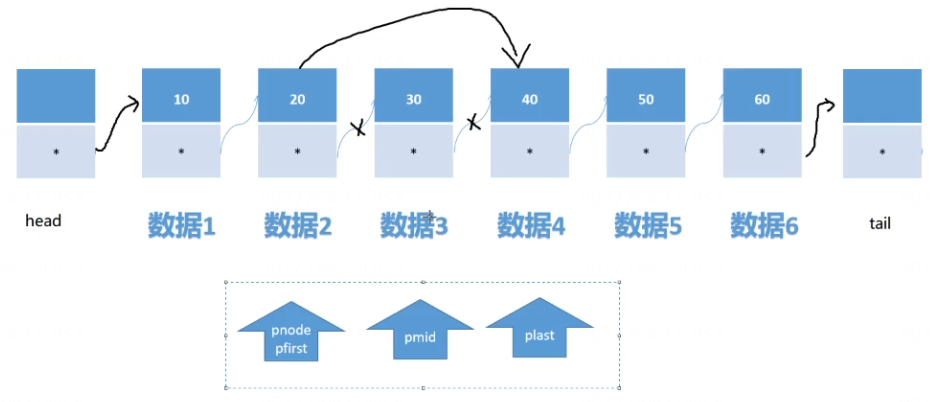
//删除某个结点的函数
void list_del(list_t* list, int data){
//head---->10---->20---->30---->tail
// pfirst pmid plast
//1.遍历要删除的结点, 并且让pmid指向要删除的结点
for(node_t* pnode = list->head; pnode != list->tail; pnode = pnode->next){
//1.定义三个游标
node_t* pfirst = pnode;
node_t* pmid = pfirst->next;
node_t* plast = pmid->next;
if(pmid->data == data && pmid != list->tail/*不能将尾结点删除*/){
pfirst->next = plast;//连接前一个结点和后一个结点
free(pmid);//释放要删除的结点内存
//pmid = NULL;
break;
}
}
}
//定义释放链表所有结点的函数
void list_deinit(list_t* list){
node_t* pnode = list->head;
while(pnode){
node_t* ptmp = pnode->next;//临时分配下一个要删除的结点
free(pnode);//释放结点内存
pnode = ptmp;//准备释放掉下一个结点
}
}
vim main.c
include "list.h"
int main(void){
//创建单链表
list_t list;
list_init(&list);
//各种插入和遍历
list_add(&list, 10);
list_add(&list, 20);
list_add(&list, 30);
list_add(&list, 40);
list_travel(&list);
list_add(&list, 80);
list_add(&list, 50);
list_add(&list, 90);
//删除结点
list_del(&list, 30);
list_travel(&list);
//释放单链表
list_deinit(&list);return 0;}
